Whenever I go to a burger restaurant & I want to order myself a nice and tasty burger. The first thing I do is look at the menu and ask myself the question: “Where is the bacon?”. I did the same thing while looking at the menu of the new up and coming SQL Server 2016, and found the nice tasty bacon in the form of a feature called Query Store!
While looking at the menu of problems with poor performing servers, one of the most common problems is vegetable like code, or vegetarian indexes. Mostly bacon like indexes & code are not to be found. If you want to troubleshoot this, you will have to analyze the system for a long time, write a lot of code to capture query plans & how they change, and analyze the impact you make by rewriting it to bacon code & adding steak indexes. Also something that happens a lot is when you visit a client, they just rebooted the system and almost all the juice for troubleshooting your SQL Server performance is gone.
They fixed this in the new SQL Server 2016 with the Query Store! Analyzing your SQL Server Query Performance has become much easier and Query data is now persisted even when they choose to reboot your SQL Server Instance!
How did they do this?
Well the guys at Microsoft decided to deliver an option for every SQL Server 2016 database called Query Store, when you enable your QS for your database, SQL Server will capture data for every query which is executed against that database. I’ll continue now by showing you how you turn on Query store. After that I’ll show you how you can track a query with Query Store!
Let’s start of by creating a new database
CREATE
DATABASE [QueryStoreDatabase]
CONTAINMENT =
NONE
ON
PRIMARY
( NAME =
N’QueryStoreDatabase’,
FILENAME
= N’F:\DATA\MSSQL\Data\QueryStoreDatabase.mdf’
, SIZE = 131072KB , FILEGROWTH = 65536KB )
LOG
ON
( NAME =
N’QueryStoreDatabase_log’,
FILENAME
= N’F:\DATA\MSSQL\Data\QueryStoreDatabase_log.ldf’
, SIZE = 65536KB , FILEGROWTH = 65536KB )
GO
As you execute this code, nothing special happens, you just create a basic database
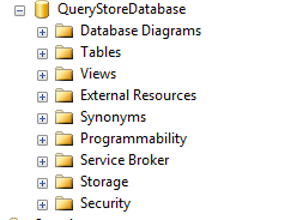
If you right click your database and select properties, you can see a new tab there called Query Store
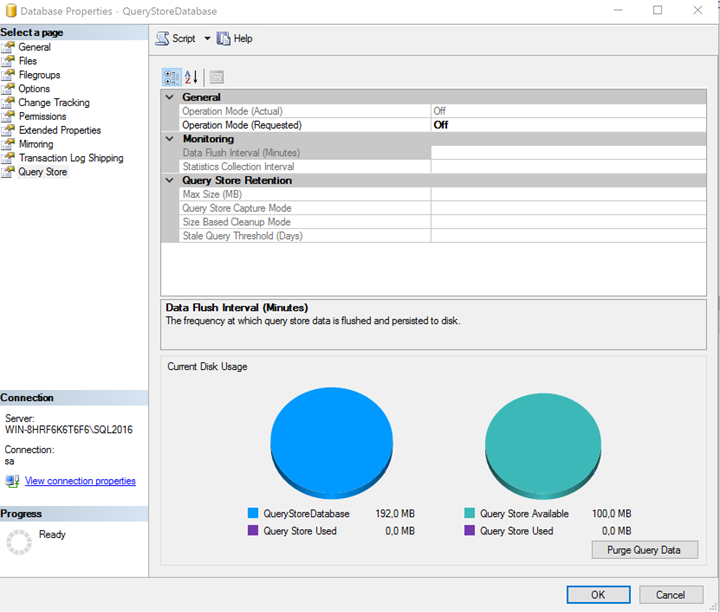
By default, SQL Server will turn off Query Store, to enable Query Store, you have to choose Read Write, this will allow SQL server to write query data into your query store, if you choose read you can only analyze the data, SQL server will not refresh the query data.
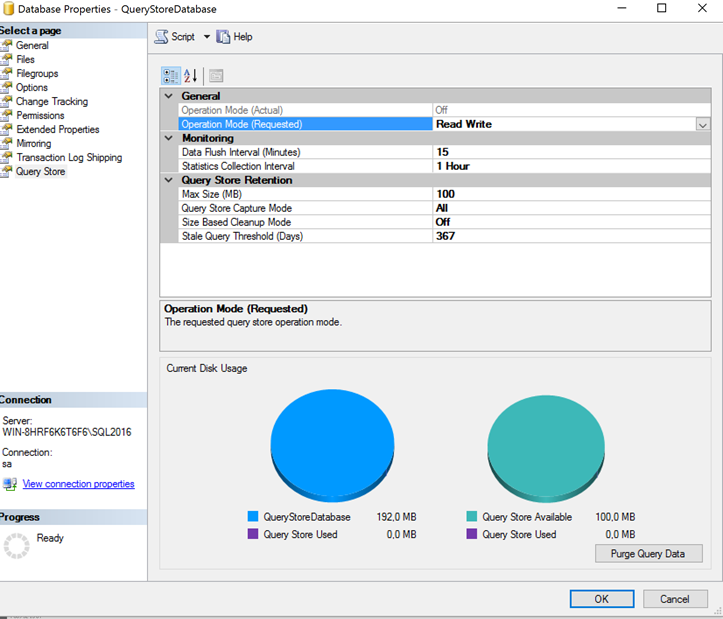
We continue by turning on Read Write, after this you can configure some other options for your QS, you can alter the interval in which it will flush data for QS and in which interval it will collect your data. I will alter this to 5 minutes for this blogpost, to be able to show data after 5 minutes. I will leave the Query Store Capture mode to all and leave Size based Cleanup mode off. By default, QS will keep 367 days of query data.
You can also give a Max Size, this is the amount of space in your database that will be made available for QS, this means that the data is stored inside of your database files. In the left of the two graphs in the bottom you can see your database size, and the size of your query store against it, in the right graph you can see the available space of query store, and the amount used.
Click OK and then continue by entering this code, this will create a table and put some data into it.
DROP
TABLE
IF
EXISTS [dbo].[QueryStore]
— Cool New Syntax for IF EXISTS
GO
CREATE
TABLE dbo.QueryStore
(
QSID int
identity(-2147483648,1),
SomeText varchar(200),
SomeCategory varchar(40)
)
GO
SET
NOCOUNT
ON;
DECLARE @Count int
SET @Count = 1
while @Count <= 10000
BEGIN
IF @Count <= 2500
BEGIN
INSERT
INTO dbo.QueryStore
VALUES (‘TEXT’+cast(@Count as
varchar),‘2500’)
END
IF @Count > 2500 and @count <= 5000
BEGIN
INSERT
INTO dbo.QueryStore
VALUES (‘TEXT’+cast(@Count as
varchar),‘5000’)
END
IF @COUNT > 5000
BEGIN
INSERT
INTO dbo.QueryStore
VALUES (‘TEXT’+cast(@Count as
varchar),‘10000’)
END
SET @Count = @Count + 1
END
GO
INSERT
INTO dbo.QueryStore
select SomeText,SomeCategory from dbo.QueryStore
GO 9
CREATE
CLUSTERED
INDEX [CI_ID] ON [dbo].[QueryStore]
(
[QSID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE =
OFF, SORT_IN_TEMPDB
=
OFF, DROP_EXISTING
=
OFF, ONLINE
=
ON, ALLOW_ROW_LOCKS
=
ON, ALLOW_PAGE_LOCKS
=
ON)
We just created a database with a table called QueryStore. Now let’s query that table and track it to see if we can improve its performance.
Execute the following query
USE [QueryStoreDatabase]
select SomeText from dbo.QueryStore where SomeCategory =
‘5000’
GO
And continue by checking your query store data
select query_id,query_sql_text from
sys.query_store_query a
inner
join
sys.query_store_query_text b on a.query_text_id =B.query_text_id
where b.query_sql_text =
‘(@1 varchar(8000))SELECT [SomeText] FROM [dbo].[QueryStore] WHERE [SomeCategory]=@1’

Use the query id to open the Tracked Queries query store reports, this is a new tab on database level.
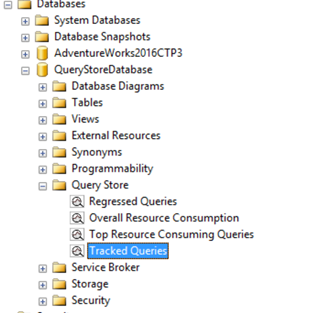
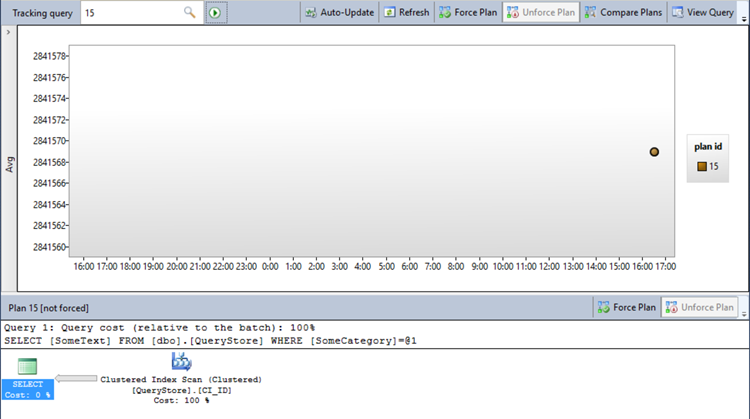
Here you can see our query which has a plan ID and duration. We are now going to continue by adding an additional index to get the query to run faster.
CREATE
NONCLUSTERED
COLUMNSTORE
INDEX [NCI_ColumnStore] ON [dbo].[QueryStore]
(
[QSID],
[SomeText],
[SomeCategory]
)WITH (DROP_EXISTING = OFF)
GO
After adding the index rerun the following query
select SomeText from dbo.QueryStore where SomeCategory =
‘5000’
And go back to the tracked queries!
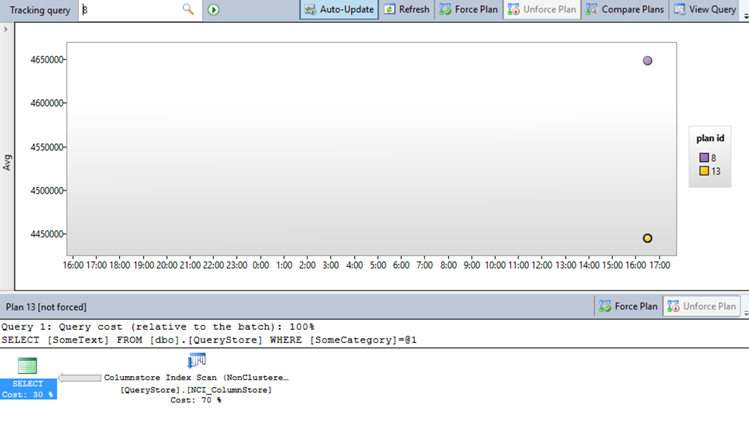
As you can see our column store was a lot faster! This is now a basic toolset you can use in your SQL Server! You can now easily track changes you make to a query and immediately see the impact you are making.
This is a feature which has got me really excited for SQL Server 2016, this is a real game changer for Query tuning!
Thank you all for reading & stay tuned!