Introduction
Today I will be showing you the do’s and don’ts when loading data into staging tables in Azure Synapse SQL Pools. This process should go as fast as possible and I would like to use this post to highlight all the things you can do to decrease the time spent on loading to stage.
Setting the stage!
To test out the different options, I will be using the TLC Trip record data which can be found at https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
I have prefetched the data from the website above and pushed this into a parquet folder. This folder contains the following files:
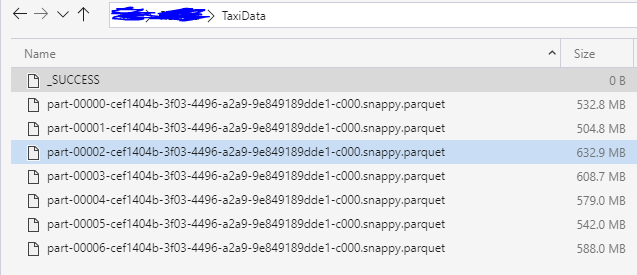
Using serverless SQL Pool, I can quickly explore the parquet files and show you how much data we will be using for testing purposes (This is using an external table specified in SQL On demand, but more on that in a later blog post).
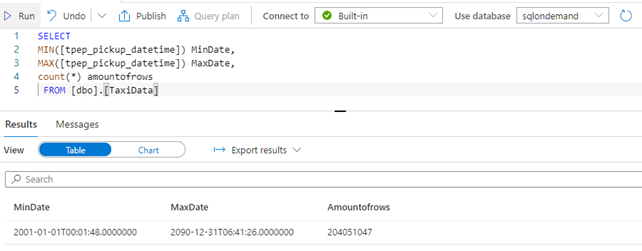
As you can see, we are going to load over 200 million rows to a table in our Azure Synapse SQL pool. This Synapse SQL pool has been scaled to 500DWU.
Resource Class
When loading data to Synapse SQL Pools, one of the first things you need to check is the resource class your loading user belongs to. By default, this will be the smallrc dynamic resource class. This resource class has a limited amount of resources to increase concurrency. More information can be found over here (https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/resource-classes-for-workload-management)
For this blog I have created a new user which is a member of the xlargerc group: the largest builtin dynamic resource class. I want the loading process to have the most resources available without specifying specific workload groups (more info: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-workload-isolation).
As a rule of thumb, the users who are running the load against your SQL Pools, should be a member of a higher resource/lower concurrency workload group to ensure that the resource intensive actions go as fast as possible.
Distribution Method
The second thing you will need to check is the distribution method you are using for the table you are going to write to; today we will be simulating the load to a staging table. In most cases this data will be truncated and then reloaded for each load process.
I will be using a SQL Pool table which has a clustered column store index, and which is distributed in round robin fashion. Round Robin will evenly distribute the data across all 60 distributions. If we use hash distribution on a specific key column, we will introduce a new overhead to the stage load process as data must be distributed based upon that column.
As a general recommendation, I would suggest using round robin for your staging tables, as this allows you to get the data into the SQL pool as fast as possible. (There are cases when you want to hash distribute, but these are not in scope of this blog)
Loading Data
To start off, I will be creating a pipeline in the orchestrate part of my Azure Synapse Studio. In this pipeline I will create a copy data task, where the source is pointing to the folder containing the parquet files. This is a very common pattern that is used when loading data to Synapse SQL Pools.
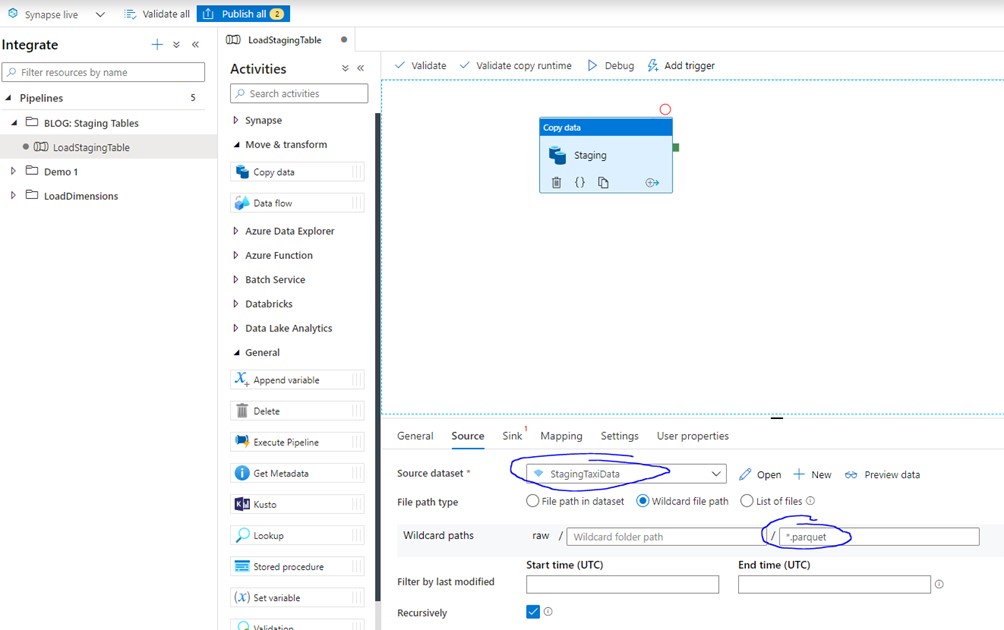
For a sink definition, I will be specifying an Azure SQL Pool table which has the following syntax:
CREATE
TABLE staging.[txdata](
[VendorID] [int] NULL,
[tpep_pickup_datetime] [datetime2](7) NULL,
[tpep_dropoff_datetime] [datetime2](7)NULL,
[passenger_count] [int] NULL,
[trip_distance] [numeric](10, 2)NULL,
[RatecodeID] [int] NULL,[store_and_fwd_flag] [varchar](8000)NULL,
[PULocationID] [int] NULL,
[DOLocationID] [int] NULL,
[payment_type] [int] NULL,
[fare_amount] [numeric](10, 2)NULL,
[extra] [numeric](10, 2)NULL,
[mta_tax] [numeric](10, 2)NULL,
[tip_amount] [numeric](10, 2)NULL,
[tolls_amount] [numeric](10, 2)NULL,
[improvement_surcharge] [numeric](10, 2)NULL,
[total_amount] [numeric](10, 2)NULL,
[congestion_surcharge] [varchar](8000)NULL)
WITH (DISTRIBUTION = round_robin,clustered columnstore index)
When selecting the synapse SQL Pool sink, you get three copy methods. These three methods will impact the speed when loading the table.
Bulk insert
For the first test I will be choosing bulk insert without changing any parameter except for truncating the table before the execution. Bulk insert will automatically assume the batch size needed to commit the data into the table. This method will not use parallelism and will execute a bunch of bulk inserts in a serialised way.
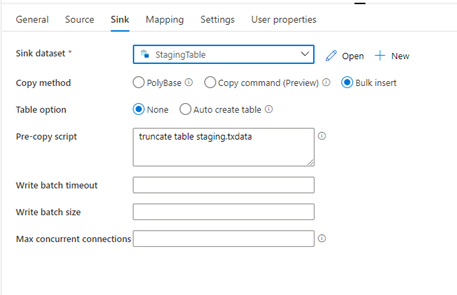
While this was running, it already points me to PolyBase to increase load performance.
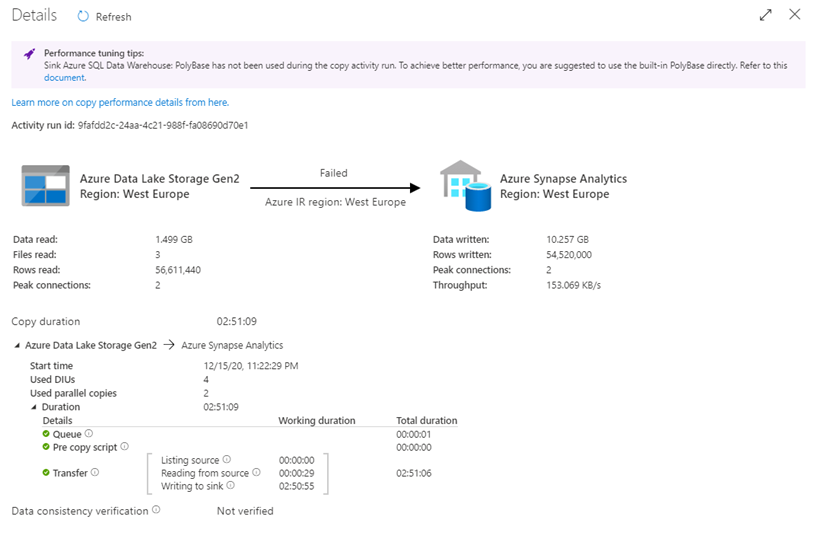
After running for 2 hours and 50 minutes I reached my threshold(configurable) and the batch failed. I feel that this is not an optimal way of loading, so let us start optimizing.
The options we have for optimizing the bulk insert mode are write batch size, and trying to drive the bulk insert process to go in a parallel way. I altered the batch size to the sweet spot of inserting compressed segments, which is a batch of 1.048.576 (Depends on a couple parameters for your data set) and I’ve built a logic around the multiple parquet files and loaded them in parallel.
You can achieve this parallelism by leveraging the GetMetadata functionality within a pipeline. In combination with a ForEach iteration, The GetMetadata task will fetch the childitems of a folder, and the foreach loop can use this output to create a parallel stream of pipelines based on the child items.
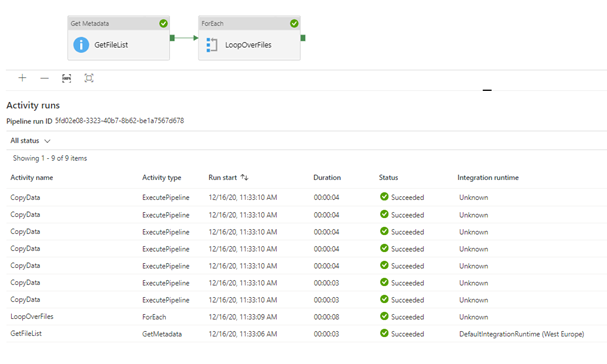
As you can see above, we are now executing all the files in parallel.
With this parallelism of files, we achieve the following result:
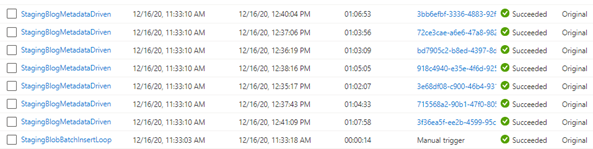
We reduced the load to 1 hour and six minutes from going into error after reaching the threshold after 2 hours and 50 minutes.
This is already a substantial increase; however, this is not yet the fastest method.
Polybase
The next method I will use to increase the load speed is PolyBase. By checking the PolyBase box, the load process will be optimized to load a large amount of data into SQL Pools with high throughput. My data is in Azure Data Lake Storage Gen2 and my format is PolyBase compatible which enables direct copy with PolyBase. If this is not the case, you will have to do a staged copy which will decrease the overall throughput of the load. To check compatibility: https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-sql-data-warehouse#direct-copy-by-using-polybase.
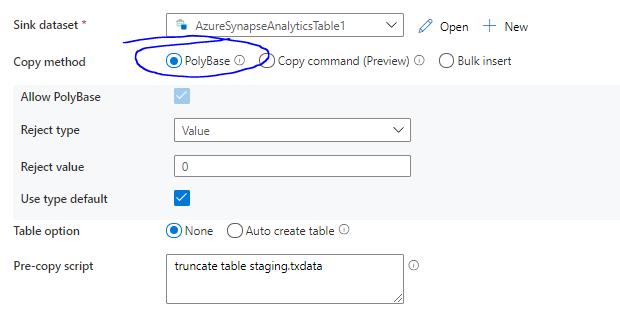
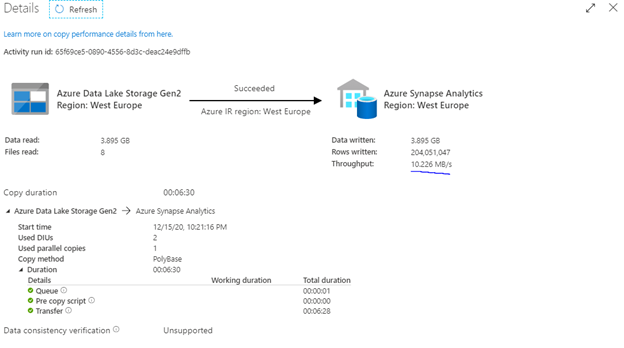
As you can see in the image above, we decimated the time we spend loading to the synapse SQL pool. With only 6 minutes and 30 seconds, the PolyBase load is 10x faster than the optimized bulk insert load! This is due to the way PolyBase works as it will act as a virtualization layer for the flat files which are in the ADLS/blob store allowing them to be presented to the SQL pool as an external table. This allows us to leverage parallelism and stream the data into the table.
This translates to the following query in the background:
INSERT INTO [staging].[txdata](
[VendorID]
…
,[congestion_surcharge] )
SELECT [VendorID]
…,
[congestion_surcharge]
FROM [ADFCopyGeneratedExternalTable_985446b7-2223-4e1b-88f9-08f0327dc0d2]
OPTION (LABEL = ‘ADF Activity ID: 9b891d04-5325-4f30-bc7a-fb00cea0fcb3’)
Copy Command
The next test will use the Copy Command this should have the same process as the PolyBase direct copy, but for completeness of the tests I will also execute this run.
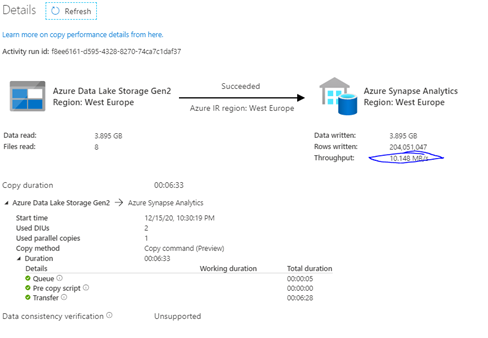
As expected, this does not change the throughput as both queries are using the HadoopRoundRobinOperation and the same insert mechanism.
COPY COMMAND
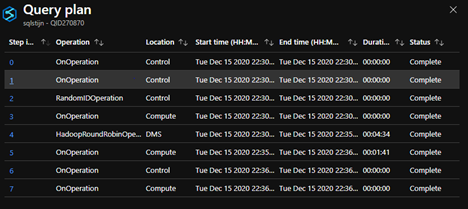
POLYBASE
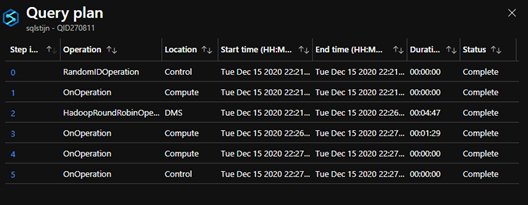
As you can see Copy Command has more steps, but they do not take any time, the time is being spend in the Hadoop operation and writing to the SQL pool table.
CTAS with an external table
The last and final test I am going to do is specifically use an external table (PolyBase) as a source for my staging table. This staging table will be dropped and recreated using the Create Table as Select statement, which should increase the load speed as well as this is a minimally logged operation and would remove the operation after the HadoopRoundRobinOperation which is the fully logged insert into an existing table.
To test this, I created the following stored procedure:
CREATE PROCEDURE CTASSTAGING AS
BEGIN
CREATE TABLE staging.txctas
WITH (DISTRIBUTION = ROUND_ROBIN, CLUSTERED COLUMNSTORE INDEX)
AS
SELECT
*
FROM [dbo].TaxiDataStaging
END
The dbo.TaxiDataStaging table has the following syntax
CREATE EXTERNAL TABLE [dbo].[TaxiDataStaging](
[VendorID] [int] NULL,…,[congestion_surcharge] [varchar](8000)NULL)
WITH (DATA_SOURCE = [SQLStijn], LOCATION = N’/TaxiData/’,FILE_FORMAT = [snapparquet],REJECT_TYPE = VALUE,REJECT_VALUE = 0)
The data source is pointing to my Azure Data Lake storage and the file format is a parquet file format. More info on external tables: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-external-table-transact-sql?view=sql-server-ver15&tabs=dedicated.
I have added a pipeline which will run my stored procedure.
This result is even faster than the previous load using PolyBase!
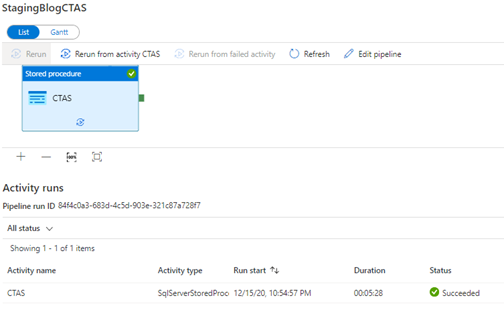
With only 5 minutes and 30 seconds, we were able to reduce the load time to the staging time with another minute! This is again a decrease by 15%.
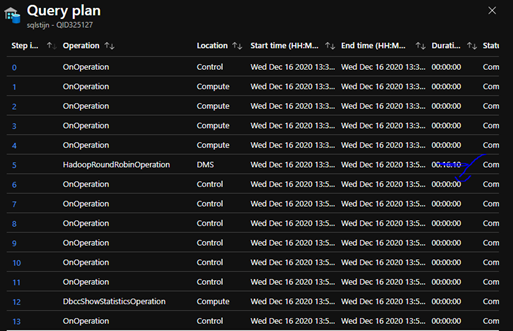
When we look at the query plan, we see that the latter step no longer takes time due to the CTAS minimally logged operation, and we only spend time in the HadoopRoundRobinOperation.
Conclusion
To conclude we see that loading using default bulk insert is not the most optimal way of loading to an Azure Synapse SQL Pool. This method for this test is 105 times slower than the Polybase load, and 136 times slower than the CTAS Load.
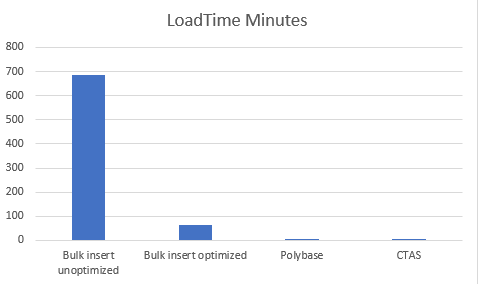
When comparing PolyBase to an existing table and PolyBase with CTAS, this is again 15% faster for this specific test. Depending on your data this might increase!
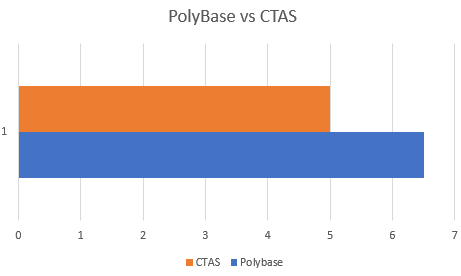
To achieve the most optimal load speed when loading data to Azure Synapse SQL Pool staging tables from ADLS or blob, using PolyBase in combination with CTAS is the way to go. This will require a Stored Procedure using dynamic code as the Copy Data task in Azure Data Factory, for example does not allow you to invoke CTAS. This will always be a fully logged operation with PolyBase.
Thank you for reading!
![]()