Today we will be exploring a new functionality in SQL SERVER 2014 Enterprise edition. This new feature is called the Clustered Columnstore index. In SQL 2012 we already got a “preview” with the NON-clustered columnstore index. But the concept has drastically changed with the new Clustered columnstore index.
In this post I will be talking about the difference with the old columnstore index, the internals of the Clustered columnstore index & when to use the clustered columnstoreindex.
- What’s the difference with Non-clustered Columnstore Index?
The most annoying thing with the old NON-clustered columnstore index was that it could not be updated. This major issue has been solved with the new Clustered columnstore index which makes it updatable. Also schema modifications are now available.
With the 2012 version there were only a limited number of data types supported. This has been fixed in the 2014 version.
Only the following datatypes are not yet supported with the clustered columnstore index: Text, Timestamp, HierachyID, SQL_Variant, XML, (n)Varchar(MAX), Geography, Geometry.
Even though the compression of the non-clustered columnstore index was impressive this has also been improved on the SQL 2014 version, with the archival compression.
- What’s going on under the hood of the SQL SERVER when working with Clustered Columnsstore index?(TUPLE)
As we know the 2012 columnstore index was not updatable, how did they fix this in the 2014 version?
Well actually they did not make the Columnstore table updatable, they just store the newly updated data into a delta store, which is a normal rowstore segment. After this they mark the old row in the columnstore for deletion. When this delta store reaches a threshold (1048576 rows), it becomes a closed segment which is marked to be inserted into the clustered columnstore index, after this a new delta store is created for new inserted/updated rows.
However if a row is currently stored into a DeltaStore and it is then updated, a normal update of the deltastore will occur.
When does this insertion occur?
This is handled by a mechanism called the tuple mover which is a background process which runs every 5 minutes or it can be triggered manually by rebuilding the table. The tuple mover will look for closed segments of the deltastore and then insert these values into the clustered columnstore index, it will also delete the rows which are marked for deletion and it will remove updated rows from the clustered columnstore which were stored in the delta store. As said before the tuple mover will look for closed segments which are delta stores which have reached the size of 1048576 rows.
This is the scenario for when we do normal inserts.However when we do a bulk insert, the segment handling becomes a different story.
When you do a bulk insert the threshold for the deltastore is only 100 000 rows. Afterwards the delta store will be marked as closed and will wait for the tuple mover to insert them into the Clustered columnstore table.
The tuple mover will not block any read scans of the data but it will block deletes and updates which are running at the moment that the tuple move comes into action. But for a datawarehouse system this should not present major blocking issues, and that is the system for which the clustered columnstore index is intended but more on that later in this post.
I will now continue with a small presentation of the delta store/tuple mover in action.
First I will create a new table and insert 1 200 000 rows.
—Create a test table
Create
table TestTuple
(
c1_ID int
not
null,
c1_Product varchar(100)
not
null
)
—Create the clustered columnstore index
create
clustered
columnstore
index ix_test on testtuple
—Insert 1 200 000 rows
DECLARE @teller int
SET @teller = 1
while @teller <= 1200000
begin
insert
into TestTuple
(c1_ID,c1_Product)
values(@teller,
‘Productje’)
set @teller = @teller + 1
end
—Check the tuple move
select
*
from
sys.column_store_dictionaries;
select
*
from
sys.column_store_segments;
select
*
from
sys.column_store_row_groups;
After this when we check the DMV we can see that in the table there is a Delta store that is marked as closed which will get updated by the tuple mover to the table and 2 delta stores which are open in which newly inserted data will be put
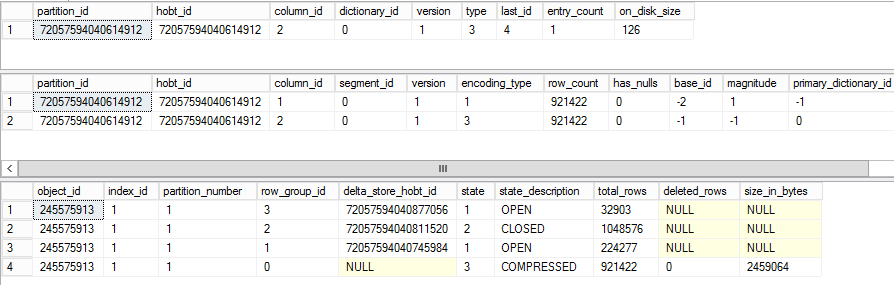
We can see when we rebuild the table, the deltastore becomes inserted into the columnstore
—Rebuild the table
Alter
table testtuple rebuild
—rerun dmv the tuple move
select
*
from
sys.column_store_dictionaries;
select
*
from
sys.column_store_segments;
select
*
from
sys.column_store_row_groups;
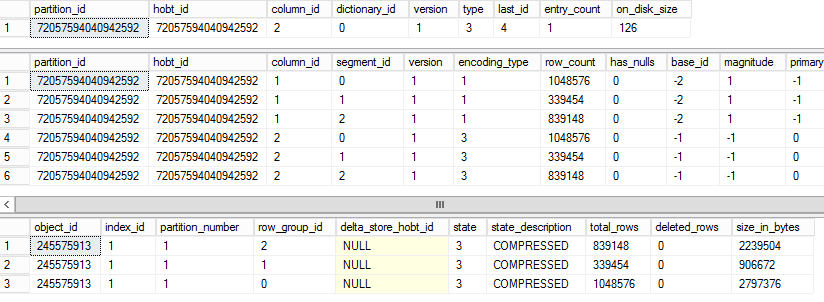
What happens when we delete data from the table?
What happens if we delete about 120 000 records
—Delete data from table
delete
from testtuple
where c1_id < 40000
- I got the data three times in my table that’s why I have 40000
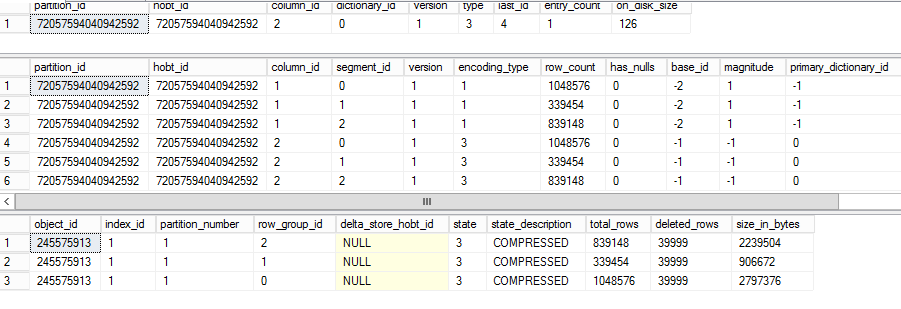
As you can see no data has actually been deleted. But we have rows which are marked for deletion.
—Select data where id < 40000
select
*
from testtuple where c1_id < 40000
We can’t query this data because the rows that are marked for deletion are stored in a bitmap which is checked before any query is executed.
Now let’s see what happens when we update the data?
—Update data where id
update testtuple
set [c1_Product] =
‘ProductjeV2’
where c1_id > 40000 and c1_id < 80000
—rerun dmv the tuple move
select
*
from
sys.column_store_dictionaries;
select
*
from
sys.column_store_segments;
select
*
from
sys.column_store_row_groups;

—Select updated data
select
*
from testtuple where c1_id > 40000 and c1_id < 80000
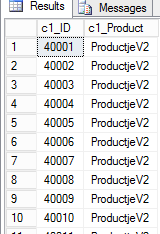
As we can see the rows have not been updated, but they are just added to a new deltastore which is open because we have not yet reached our threshold.
If we update the same rows again we will see another behavior.
—Update data where id
update testtuple
set [c1_Product] =
‘ProductjeV3’
where c1_id > 40000 and c1_id < 80000
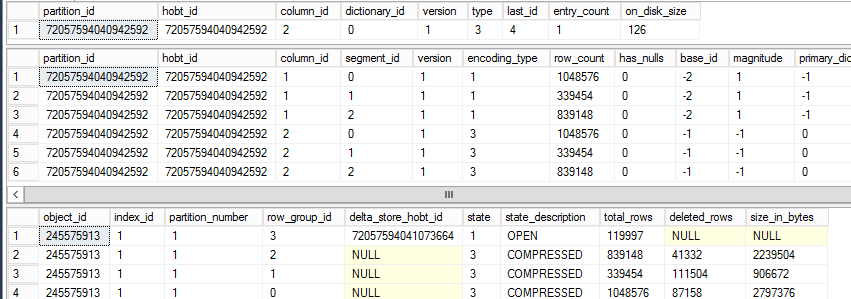
As we can see the amount of rows in the deltastore stays the same. We continue by selecting the updated data
—Select updated data
select
*
from testtuple where c1_id > 40000 and c1_id < 80000

So only when we are updating newly inserted/updated rows we are actually updating the rows, otherwise the current rows just get marked for deletion and will be skipped in the query and only the latest updated value is shown.It is the same case for deleting rows, we will not see the deleted rows but they are still stored in the table. Only after the tuple move comes into action or if we rebuild the table/index the rows are inserted or deleted in the CCI.
-
What table should I use for the clustered columnstore index?
So for which systems should we use the clustered columnstore index? This answer is quite straightforward: Datawarehouse systems. Clustered columnstore index is perfect for big fact tables which are used for aggregating lots of values. Also with the new compression the size of your fact tables can be drastically lowered. For an OLTP system the clustered columnstore index is not a good thing because the tuple mover might cause serious blocking and the CCI will actually perform worse when seeking single rows. But more on that in a future post.
Thanks for reading, in the next posts I will be covering the performance of the new CCI and other new features in SQL SERVER 2014 like the in-memory tables. Stay tuned!