Welcome to the third post of the blog series I am writing on Azure Synapse Analytics. As you know Azure Synapse Analytics went GA December of 2020, and in the following blogposts I would like to walk you through the out-of-the-box capabilities you have to report easily on a vast dataset.
Azure Synapse Analytics series
- Azure Synapse Analytics – Serverless SQL Pools
- Azure Synapse Analytics – Serverless SQL Pools: Partitioning
- Azure Synapse Analytics – Serverless SQL Pools: Data Elimination
Setting the stage
When working with serverless SQL Pools, reducing the amount of data read reduces the cost of the overall solution. In today’s post, we will be testing out what happens to the amount of data processed depending on column selection & column filters.
For these tests I have prepped the taxi dataset in two ways.
- Basic folder structure with no alterations
- Folder written with order by PULocationID
df = spark.read.load('abfss://taxi@storageaccount.dfs.core.windows.net/TaxiNP/', format='parquet')
df.createOrReplaceTempView("Taxi")
writedf = sqlContext.table("Taxi").sort("PULocationID")
writedf.write.format("parquet").save("abfss://taxi@storageaccount.dfs.core.windows.net/PULocationID/")Testing the amount of data read with serverless SQL Pools
I will start off by writing a query showing the distinct amount of PULocationID in total and by file for both datasets.
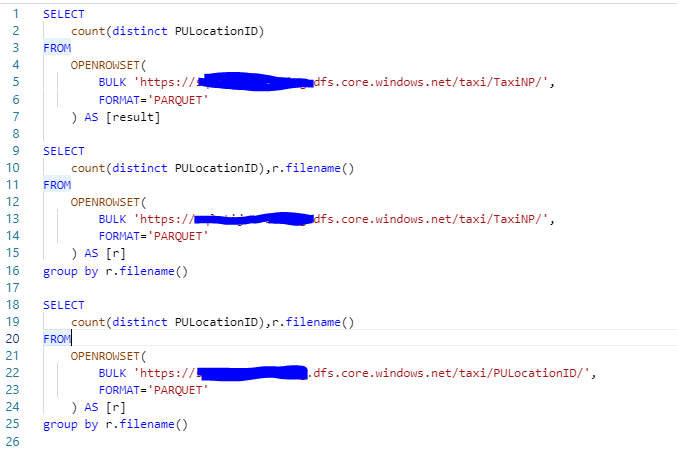
When checking the results, we see that we have 266 distinct PULocationID’s
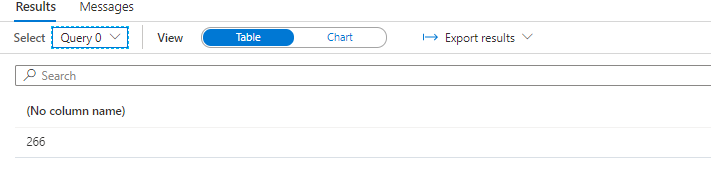
In the TaxiNP dataset we see that all PULocationID’s are in almost all files
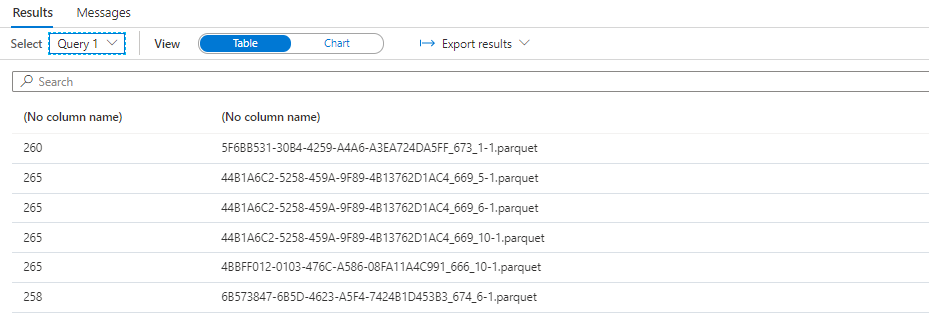
In the PULocationID dataset we see that each file contains between 1 and 2 PULocationID’s
We proceed by creating two views, one for the TAXINP folder and one for the PULOCATIONID folder
The first test: All columns vs Limited amount of columns
The first test we will be doing is an obvious one, what happens if we select all columns of the view compared to a single column. We expect that the amount of data read when selecting fewer columns should be less than when selecting all columns.
We will be reading from the TAXINP View and read the top 10 000 000 rows of all columns and then read the top 10 000 000 rows of just the PULocationID

As expected, the amount of data read has a vast difference, this also translates in the time the query was executing. So selecting only the columns you need will reduce the amount of data read and reduce the execution time. It seems that select * is still a bad option

The second test: filtering the data with a where clause
For the second test we need to have a bit more context, I have created my PULocationID view dataset based on files that are ordered by PULocationID. This means that files will contain only the rows of a certain set of PULocationID’s.
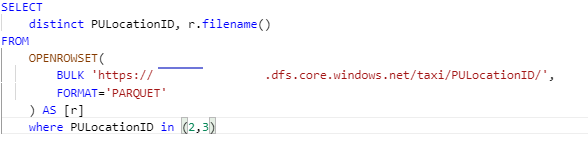
If we read from the view and list the filename with it using the filename() function of openrowset, we can see that one file contains all values for PULocationID 2 and 3

We will now dive into some pyarrow code to get the metadata of the rowgroups in the parquet file
from azure.storage.blob import BlobServiceClient, BlobClient, ContainerClient
import pyarrow.parquet as pq
from io import BytesIO
filename = "part-00001-82448f9c-6320-4d40-a5e2-a4e44ff498a3-c000.snappy.parquet"
CONNECT_STR = "yourconnectionstring"
container_name="taxi"
blob_service_client = BlobServiceClient.from_connection_string(CONNECT_STR)
container_client=blob_service_client.get_container_client(container_name)
blob_client = container_client.get_blob_client(filename)
streamdownloader=blob_client.download_blob()
stream = BytesIO()
streamdownloader.download_to_stream(stream)
PyArrow = pq.ParquetFile(source=stream)
PyArrow.metadata
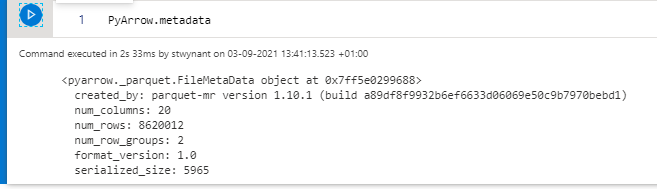
This code will list the metadata of the parquet file, as you can see we have two row groups, if we dive a bit deeper and check the column chunks for each one of these row groups(using metadata.rowgroup().column()) for the PULocationID column, we see that rowgroup 0 contains the values 2 and 3 and rowgroup 1 contains only value 3.
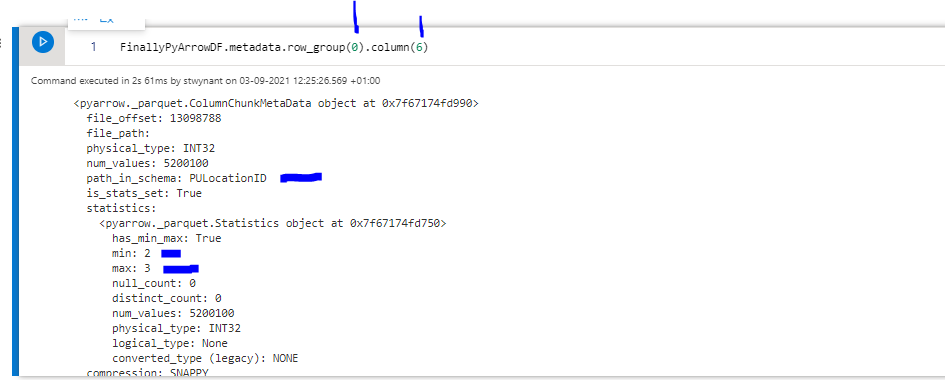
And
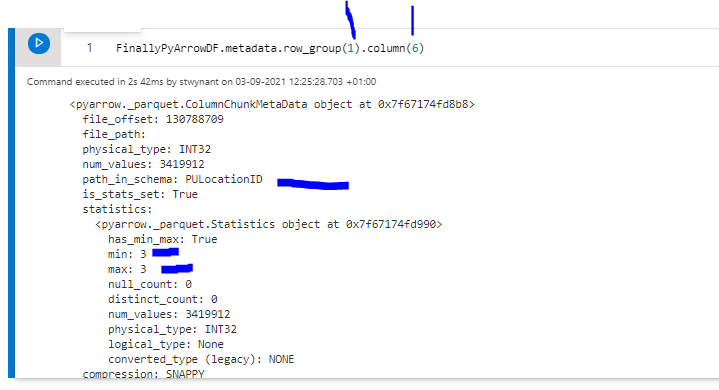
This could mean if we apply a filter based on PULocationID = 2 (One rowgroup), we should be reading less data than when we are going to apply a filter based on PULocation = 3 (two rowgroups)
Let’s see what happens when we query the data.
When we query with PULocationID = 3


When we query with PULocationID = 2

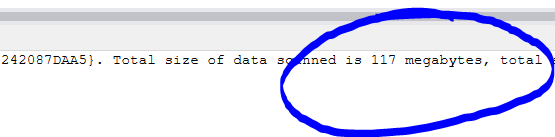
We do read less data; this means by filtering on values we also reduce the amount of data read depending on how the row groups are build.
Conclusion
When querying parquet data with serverless SQL pools, choosing the right number of columns will reduce the amount of data you process. As a general recommendation, reduce the number of columns you select where possible. Next to this we also see that applying a filter will also reduce the amount of data being read, this will be done on file level and as seen above potentially on row group level as well.
Thank you for reading and stay tuned!
![]()