Today I was creating a dummy database and wanted to fill this with a certain amount of data. Since I was going to use this database for demo purposes, I created them with foreign keys & Primary keys, and some indexes. (For my next blog on real-time analytics) But during the creation of this database I found that the way I was using to load my data was quite slow, so I decided to load the data into my database using Natively Stored Procedures and in memory tables since this should be the fastest way. The result really baffled me!
Some background information: I’m using the DELL Inspirion 5220 (http://i.dell.com/sites/doccontent/shared-content/data-sheets/en/Documents/Dell_Precision_15_5000_Series_5510_Spec_Sheet.pdf) with 16GB of ram. My virtual machine has access to all cores but is capped to 90%, and my virtual machine has 4096MB of memory & 3584 MB of memory is allocated to SQL Server. The VM is a server core with SQL server 2016. My VM is running on SSD’s.
The First Scenario which I used was loading my data into SQL Server without the usage of In memory & Natively stored procedures. ( A lot of code will follow but this way you can test it yourself)
The following script was used.
— CREATE DATABASE PART
ALTER DATABASE REALTIMEANALYTICS SET SINGLE_USER WITH ROLLBACK IMMEDIATE
USE MASTER
GO
DROP DATABASE IF EXISTS RealtimeAnalytics
GO
CREATE DATABASE [RealtimeAnalytics] CONTAINMENT = NONE
ON PRIMARY
( NAME = N’RealtimeAnalytics_1′, FILENAME = N’G:\DATA\RealtimeAnalytics_1.mdf’, SIZE = 131072KB , FILEGROWTH = 131072KB ),
( NAME = N’RealtimeAnalytics_2′, FILENAME = N’G:\DATA\RealtimeAnalytics_2.ndf’, SIZE = 131072KB , FILEGROWTH = 131072KB ),
( NAME = N’RealtimeAnalytics_3′, FILENAME = N’G:\DATA\RealtimeAnalytics_3.ndf’, SIZE = 131072KB , FILEGROWTH = 131072KB ),
( NAME = N’RealtimeAnalytics_4′, FILENAME = N’G:\DATA\RealtimeAnalytics_4.ndf’, SIZE = 131072KB , FILEGROWTH = 131072KB )
LOG ON
( NAME = N’RealtimeAnalytics_log’, FILENAME = N’C:\Data\LOG\RealtimeAnalytics_log.ldf’, SIZE = 131072KB , FILEGROWTH = 131072KB )
GO
I created a Database with 4 files called RealtimeAnalytics. Afterwards I’m adding 4 tables with keys to each other.
— CREATE TABLE PART
CREATE TABLE dbo.Clients
(
ClientID int identity(-2147483648,1)PRIMARY KEY NOT NULL,
ClientName varchar(200),
ClientCreditcard varchar(200)
)
GO
CREATE TABLE dbo.SalesPersons
(
SalesPersonID int identity(-2147483648,1)PRIMARY KEY NOT NULL,
SalesPersonName varchar(300),
SalesPersonDiscount int
)
GO
CREATE TABLE dbo.Item
(
ItemID int identity(-2147483648,1)PRIMARY KEY NOT NULL,
ItemName varchar(300),
ItemPrice numeric(15,2)
)
GO
CREATE TABLE dbo.Production
(
ProductionID int identity (-2147483648,1)PRIMARY KEY NOT NULL,
ClientID int FOREIGN KEY REFERENCES CLIENTS(ClientID)NOT NULL,
SalesPersonID int FOREIGN KEY REFERENCES SalesPersons(SalesPersonID)NOT NULL,
AmountOfItemsSold int,
ItemID int FOREIGN KEY REFERENCES Item(ItemID)NOT NULL,
DateOfSale datetime not null DEFAULT(Getdate())
)
GO
After the creation of the tables I’m going to insert data into the tables in a while loop (not the best solution but hey I will do the same thing with the natively)
—- FILL THE TABLES WITH DATA
DECLARE @Count int = 1
–FILL CLIENTS
WHILE @Count <= 1000
BEGIN
INSERT INTO dbo.Clients
select ‘Name’ +cast(@Count as varchar),‘1111-1111-111’+cast(@Count as varchar)
SET @Count = @Count +1
END
SET @Count = 1
–FILL SalesPersons
WHILE @Count <= 10
BEGIN
INSERT INTO dbo.SalesPersons
select ‘Name’ + cast(@Count as varchar), FLOOR(RAND()*(50–1)+1)
SET @Count = @Count +1
END
SET @Count = 1
–FILL Items
WHILE @Count <= 800
BEGIN
INSERT INTO dbo.Item
select ‘Item’+cast(@Count as varchar),cast(RAND()*(200000–1)as numeric(15,2))
SET @Count = @Count +1
END
SET @Count = 1
DECLARE @ClientID int
DECLARE @SalesPersonID int
DECLARE @ItemID int
–FILL Production
WHILE @Count <= 2000000
BEGIN
SET @ClientID =(select ClientID from dbo.Clients where ClientName = ‘Name’+CAST(FLOOR(RAND()*(1000–1)+1)AS VARCHAR))
SET @SalesPersonID =(select SalesPersonID from dbo.SalesPersons where SalesPersonName = ‘Name’+CAST(FLOOR(RAND()*(10–1)+1)AS VARCHAR))
SET @ItemID =(select ItemID from dbo.Item where ItemName =‘Item’+CAST(FLOOR(RAND()*(800–1)+1)as varchar))
INSERT INTO dbo.Production
select @ClientID,@SalesPersonID,FLOOR(RAND()*(100–1)+1),@ItemID,dateadd(second,–floor(rand()*(604800–1)+1),getdate())
SET @Count = @Count +1
END
When we run this script we see following workload on the machine, my C drive (SSD is getting hammered, but cpu usage is quite fine)
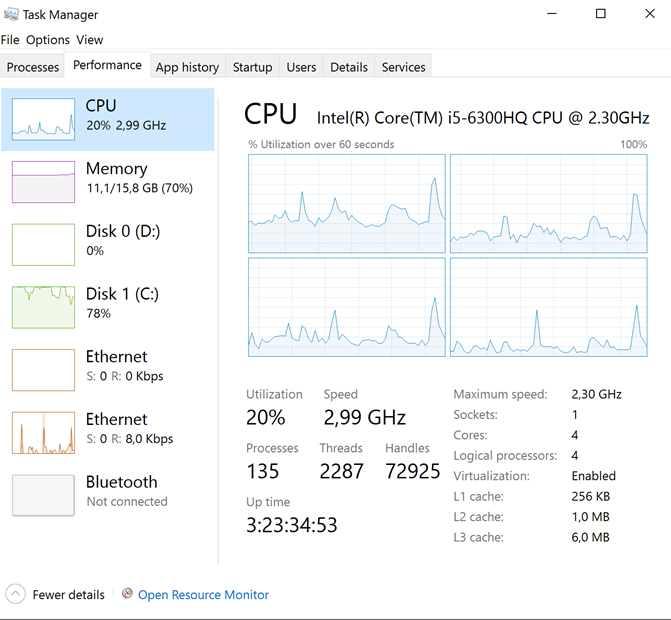
I decided to stop the script after about an hour and a half, because this was taking way to long

When I check how many records where inserted into the Production Table I see following result
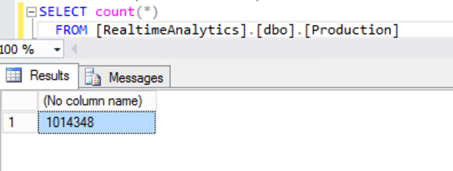
During all that time only about 1 000 000 rows were inserted, this is unacceptable. So I thought let’s use that improved Inmemory table and natively stored procedures and see what the difference is. So I edited the script with following code
On the Create database I made it Memory Optimized enabled
use master
go
alter database RealtimeAnalytics add filegroup RealtimeAnalytics_mod contains memory_optimized_data
go
— adapt filename as needed
alter database RealtimeAnalytics add file (name=‘RealtimeAnalytics_mod’, filename=‘G:\data\RealtimeAnalytics_mod’)
to filegroup RealtimeAnalytics_mod
go
I then created the same table structure but inmemory.
–MEMORY OPTIMIZED
use RealtimeAnalytics
go
CREATE TABLE dbo.Clients_MON
(
ClientID int identity(1,1)PRIMARY KEY NONCLUSTERED NOT NULL,
ClientName varchar(200),
ClientCreditcard varchar(200)
)
with (memory_optimized=on)
GO
CREATE TABLE dbo.SalesPersons_MON
(
SalesPersonID int identity(1,1)PRIMARY KEY NONCLUSTERED NOT NULL,
SalesPersonName varchar(300),
SalesPersonDiscount int
)
with (memory_optimized=on)
GO
CREATE TABLE dbo.Item_MON
(
ItemID int identity(1,1)PRIMARY KEY NONCLUSTERED NOT NULL,
ItemName varchar(300),
ItemPrice numeric(15,2)
)
with (memory_optimized=on)
GO
CREATE TABLE dbo.Production_MON
(
ProductionID int identity (1,1) PRIMARY KEY NONCLUSTERED NOT NULL,
ClientID int FOREIGN KEY REFERENCES CLIENTS_MON(ClientID)NOT NULL,
SalesPersonID int FOREIGN KEY REFERENCES SalesPersons_MON(SalesPersonID)NOT NULL,
AmountOfItemsSold int,
ItemID int FOREIGN KEY REFERENCES Item_MON(ItemID)NOT NULL,
DateOfSale datetime not null DEFAULT(Getdate())
)
with (memory_optimized=on)
Notice that I can’t set my ID to -2147483648, more info on that here : (https://msdn.microsoft.com/en-us/library/dn247640.aspx). Why would they do that?
But this is out of scope and I’m going to continue by giving you the stored proc that I created. This is exactly the same thing as I did in the previous test, only now I made a native stored proc out of it.
USE RealtimeAnalytics
GO
create procedure dbo.FillDatabase with native_compilation, schemabinding, execute as owner
as
begin
atomic with (transaction isolation level=snapshot, language=N’us_english’)
DECLARE @Count int = 1
–FILL CLIENTS
WHILE @Count <= 1000
BEGIN
INSERT INTO dbo.Clients_MON
select ‘Name’ + cast(@Count as varchar),‘1111-1111-111’+cast(@Count as varchar)
SET @Count = @Count +1
END
SET @Count = 1
–FILL SalesPersons
WHILE @Count <= 10
BEGIN
INSERT INTO dbo.SalesPersons_MON
select ‘Name’ +cast(@Count as varchar), FLOOR(RAND()*(50–1)+1)
SET @Count = @Count +1
END
SET @Count = 1
–FILL Items
WHILE @Count <= 800
BEGIN
INSERT INTO dbo.Item_MON
select ‘Item’ + cast(@Count as varchar),cast(RAND()*(200000–1) as numeric(15,2))
SET @Count = @Count +1
END
SET @Count = 1
DECLARE @ClientID int
DECLARE @SalesPersonID int
DECLARE @ItemID int
–FILL Items
WHILE @Count <= 2000000
BEGIN
SET @ClientID = (select ClientID from dbo.Clients_MON where ClientName = ‘Name’+CAST(FLOOR(RAND()*(1000–1)+1) AS VARCHAR))
SET @SalesPersonID = (select SalesPersonID from dbo.SalesPersons_MON where SalesPersonName = ‘Name’+CAST(FLOOR(RAND()*(10–1)+1)AS VARCHAR))
SET @ItemID = (select ItemID from dbo.Item_MON where ItemName = ‘Item’+CAST(FLOOR(RAND()*(800–1)+1)as varchar))
INSERT INTO dbo.Production_MON
select @ClientID,@SalesPersonID,FLOOR(RAND()*(100–1)+1),@ItemID,dateadd(second, –floor(rand()*(604800–1)+1),getdate())
SET @Count = @Count +1
END
end
After this was created I created following statement to load the data to inmemory and then switch it to my normal tables using insert into select
EXEC dbo.FillDatabase
GO
SET IDENTITY_INSERT dbo.Clients ON
insert into dbo.Clients(ClientID,ClientName,ClientCreditcard)
select ClientID,ClientName,ClientCreditcard from Clients_MON
SET IDENTITY_INSERT dbo.Clients OFF
GO
SET IDENTITY_INSERT dbo.SalesPersons ON
insert into dbo.SalesPersons (SalesPersonID,SalesPersonName,SalesPersonDiscount)
select SalesPersonID,SalesPersonName,SalesPersonDiscount from SalesPersons_MON
SET IDENTITY_INSERT dbo.SalesPersons OFF
GO
SET IDENTITY_INSERT dbo.Item ON
insert into dbo.Item(ItemID,ItemName,ItemPrice)
select ItemID,ItemName,ItemPrice from Item_MON
SET IDENTITY_INSERT dbo.Item OFF
GO
SET IDENTITY_INSERT dbo.Production ON
insert into dbo.Production (ProductionID,ClientID,SalesPersonID,AmountOfItemsSold,ItemID,DateOfSale)
select ProductionID,ClientID,SalesPersonID,AmountOfItemsSold,ItemID,DateOfSale from Production_MON
SET IDENTITY_INSERT dbo.Production OFF
While executing the last statement we can see that the workload has changed. We no longer see our disk getting hammered (Normal because we are hammering our Memory) and more CPU usage!
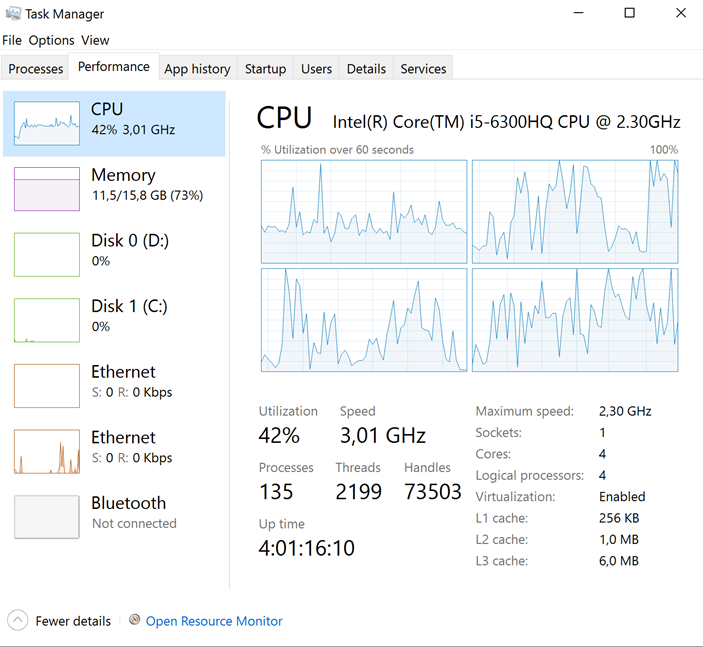
After about 8 minutes I got a ping that my query had executed. 8 MINUTES!!!!
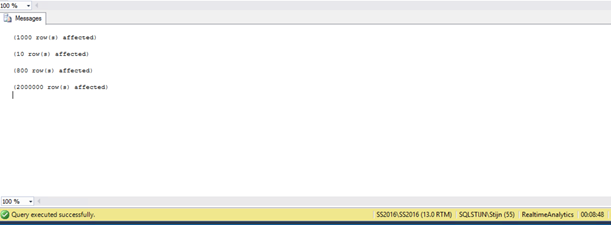
So for doing exactly the same thing but first loading them into memory I got my result in my table in 8 minutes and 48 seconds, while with the other way (No In memory tables & native procs) I only had inserted 1 000 000 rows after 1 hour and 30 minutes. This is an excellent performance gain if you ask me! To conclude, let’s just say that In memory optimized tables & natively stored procs are fast, very fast, extremely fast! If you have a high insert rate on your table and the table can’t follow I would suggest trying to implement this scenario because it might be the case that you can greatly benefit from it.
Thanks for reading and stay tuned!